Migrerad artikel
Denna artikel har migrerats från en tidigare version av vår webbplats och kan därför avvika i utseende och funktionalitet.
9 minuter
Säg att du har en URL, till exempel www.tedgustaf.se/om-oss, som du vill peka om till en annan URL, men den här sidan har också många undersidor som också ska pekas om till samma sida. Istället för att spendera tid på att lägga till varje ompekning var och en för sig, kan du sätta upp en regel som inkluderar alla sidor innehållande www.tedgustaf.se/om-oss och därmed bara behöver lägga till en ompekning.
Den metod du använder här kallas regex där specifika tecken används för att förklara vad som ska inkluderas i regeln. Varje tecken har en särskild betydelse, till exempel \ (backslash) används framför andra tecken för att förklara nästkommande teckens betydelse.
En . (punkt) i en URL måste alltså föregås av ett \ för att tolkas rätt, samma sak gäller för / (forward slash) och alla andra tecken som inte är bokstäver.
Ett bra sätt att testa sitt regex-uttryck, är via https://regex101.com/. Här kan du testa om ditt uttryck matchar dina test-strängar, slå upp vad olika tecken betyder och få hjälp om du fastnar.
I många fall när du ombeds lägga till filtrering, till exempel när du bygger personaliserade rapporter i Google Analytics, kan du använda dig av regex-uttryck för att få med endast de URL:er du är intresserad av. Även i Google Tag Manager när du sätter upp triggers är regex ett alternativ, eller när du som i exemplet i den här bloggposten ska lägga till en ompekning och vill få med specifika och eventuella URL:er.
Som nämndes i början av denna artikel, vill vi peka om www.tedgustaf.se/om-oss samt alla underliggande sidor till denna URL.
Till att börja med ska vi inkludera URL:en som matchar exakt mot föräldersidan www.tedgustaf.se/om-oss. För att testa vårt uttryck går vi till https://regex101.com/. Överst i bilden nedan ser du URL:en vi vill lägga till regex-uttryck för, för att på så sätt matcha mot de undre test-varianterna vi lagt till. Lägg även till test-strängar som du vill testa att ditt regex-uttryck inte matchar mot, så som i detta fall till exempel www.tedgustaf.se/blog/om-oss eller www.tedgustaf.se/en-dag-pa-tg/karriar.
Lägger vi inte till någonting till URL:en www.tedgustaf.se/om-oss, så kommer ingenting att matcha. Detta för att, som beskrevs ovan, det finns tecken i URL:en som inte föregås av \.
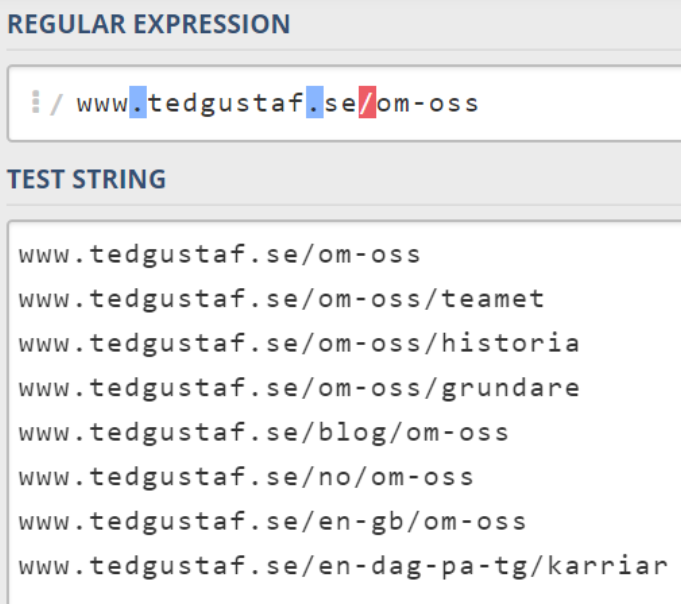
Lägger vi däremot till \ (backslash) före . (punkt) och / (forward slash) så ser vi att vi får en träff på www.tedgustaf.se/om-oss bland våra test-strängar. \ före . och / visar att dessa tecken faktiskt används som de är och att de i dessa fall inte är några specialtecken.
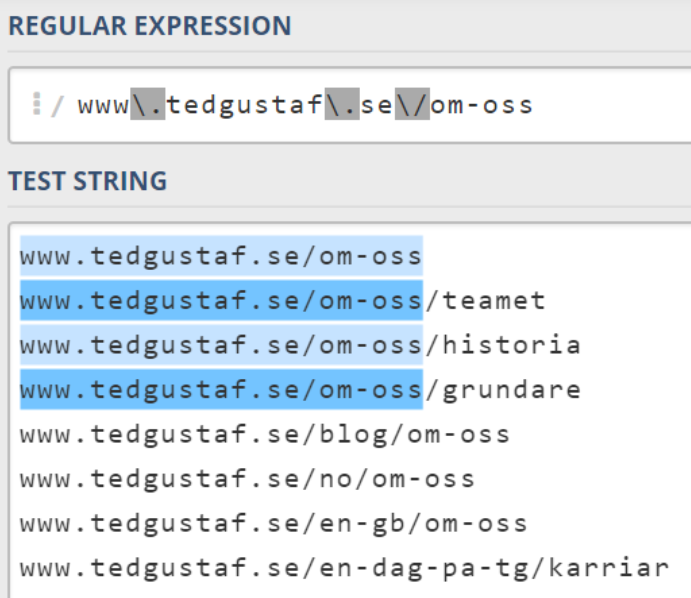
Vi ville också få med eventuella undersidor till /om-oss. Det man kan göra då är att i slutet av URL:en lägga till .* (punkt och asterisk) vilket betyder att alla eventuella efterkommande tecken ska tas med i uttrycket. Punkten står för alla tecken och stjärnan för mellan noll och oändligt många. Tillsammans blir alltså .* alla tecken mellan noll och oändligt många.
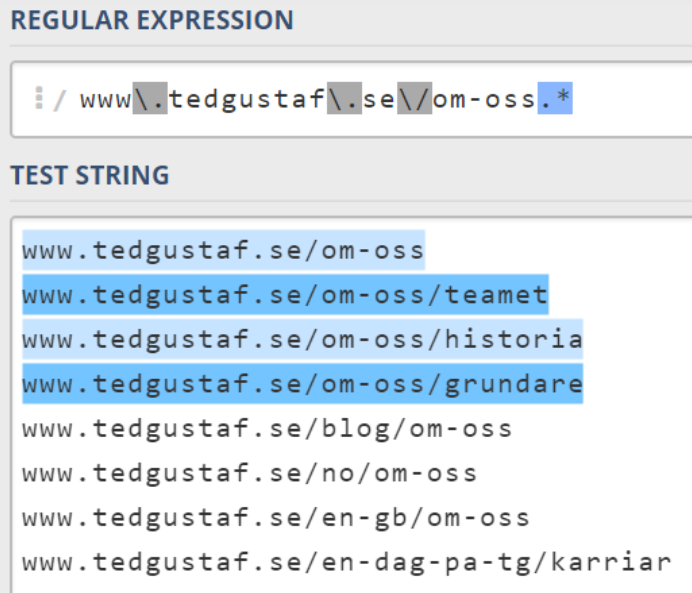
Det enda som saknas nu, är att vi inte räknat med våra eventuella språkversioner. Det skulle ju kunna vara så att vår webbplats även finns tillgänglig på engelska, norska etc. Vi bryter ned det här i flera steg för att skapa bättre förståelse kring vad som är vad.
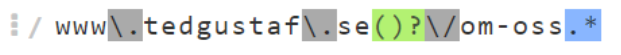



Nu har vi en träff på nästan alla URL'er vi är ute efter, inklusive URL:er inkluderande eventuella språkprefix på två bokstäver:
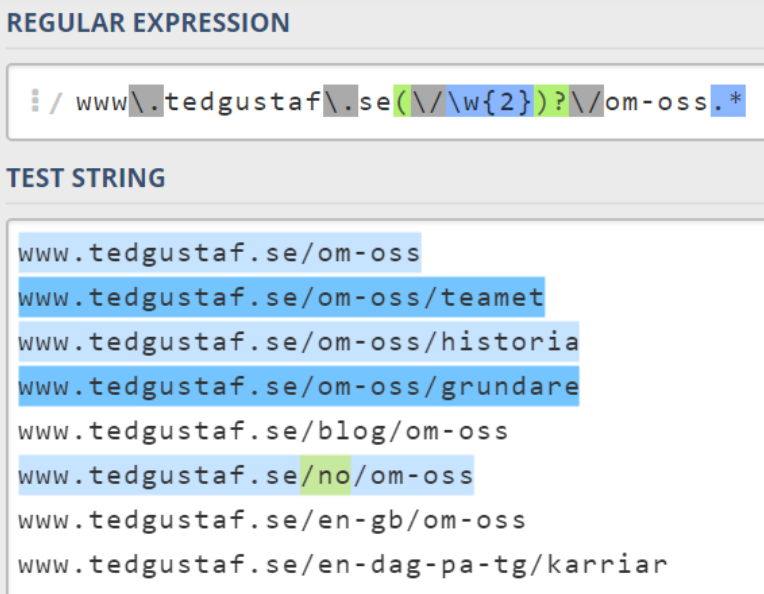
Vad händer om ett språkprefix innehåller fler tecken inkludenande bindestreck? Här har vi ett exempel som ovan regexuttryck inte skulle matcha mot.

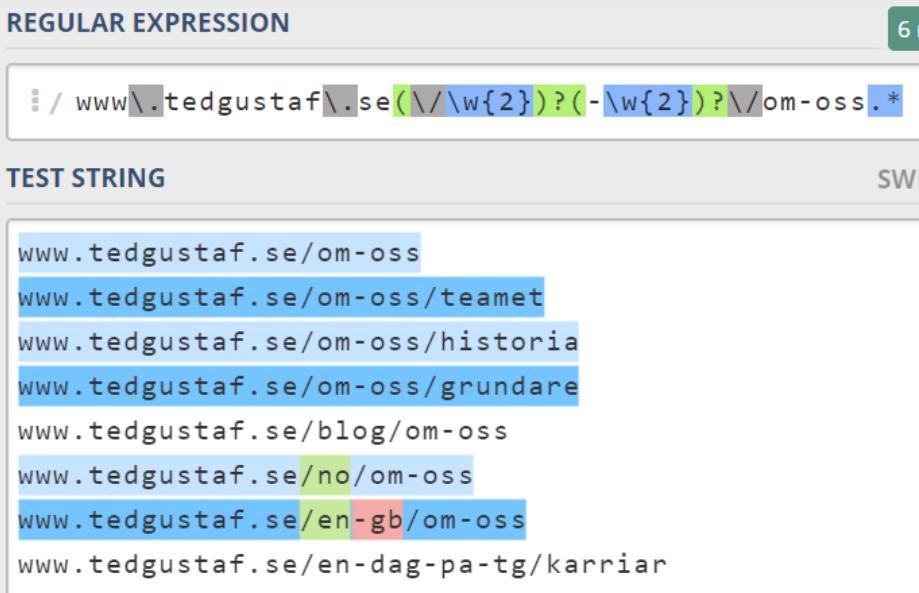
För att komma åt denna sträng, borde man ju kunna dubblera \w{2} och sätta ett bindestreck emellan. Vi testar och inser att uttrycket matchar mot /en-gb, men inte /no. I detta fall tolkas uttrycket som att i de fall då det finns ett språkprefix, så kommer det att inkludera två tecken med bindestreck emellan och sedan två ytterligare tecken. Detta eftersom allt ligger inom samma parentes.
Det vi behöver göra nu är att:
Nu får vi träffar på både /no och /en-gb!
www\.tedgustaf\.se(\/\w{2})?(-\w{2})?\/om-oss.*
Det kan verka klurigt att komma igång med regex om man är helt ny på området, men man måste inte måste komma ihåg alla teckens betydelser och kombinationer. Det bästa är att testa sig fram, med hjälp av till exempel https://regex101.com/. Regex kan verkligen underlätta i många fall som annars skulle upplevts som komplexa och kommer spara tid för både dig och dina kunder.
Hur använder du dig av Regex och vilka är dina bästa tips?
